Sam Altman says we're entering the fast fashion era of SaaS. He's right.
GPT is fast fashion. That's the business model. Cheap, fast, disposable, replaceable. Ship it Tuesday, obsolete by Thursday, ship the next one Friday. He's not hiding it. He's announcing it.
And everyone heard "fast fashion" and panicked about wrappers. It's just a wrapper. No moat. Dead the moment the provider ships the same feature natively. I've heard it enough times that I started asking myself whether it was true.
So I ran an experiment.
But here's what the wrapper panic misses: fast fashion only works if the factory is solid. The stitching, the supply chain, the delivery. That's infrastructure. And nobody's building it.
The fast fashion flood actually makes the infrastructure more valuable, not less. When every team can spin up a disposable app in an afternoon, the thing that differentiates isn't the app. It's the foundation it runs on. The more disposable the software gets, the more valuable the infrastructure underneath it becomes.
Altman is validating the framing. He's telling you GPT is fast fashion, and he's proud of it. I'm not arguing with him. I'm agreeing with him, and then pointing at what his model leaves out.
The Wrapper Critique (and Why It's Wrong)
The wrapper critique assumes the value is in the model call. If all you're doing is prompt, LLM, response, yeah, you're dead. But that logic breaks down the moment you look at any other industry.
Bloomberg Terminal vs. Excel. Figma vs. Photoshop. Stripe vs. PayPal. Avid vs. iMovie.
Every single one of these is a "wrapper" around a capability that already existed. Excel could do financial analysis. Photoshop could do UI design. PayPal could move money. But nobody calls Bloomberg a wrapper around spreadsheets. Nobody calls Stripe a wrapper around payment processing. Because the value was never in the underlying capability. It was in the workflow, the infrastructure, and the specificity of who it was built for.
The general-purpose tool can do the job. The purpose-built tool understands the workflow around the job. One serves everyone. The other serves someone specific so well they never go back.
Nobody argues this in any other domain. But for some reason when it comes to agents, everyone acts like GPT is the ceiling.
It's not. It's the floor.
The Experiment
I downloaded a Kaggle dataset. Ran it through ChatGPT. Then ran the same dataset, same prompt, through Ca$ino, the composable agent I've been building on AWS Strands.
Side by side. Same task. Same data.
Ca$ino blew it out of the water. And it was faster.
Then I ran it again in GPT's agent mode to be fair. This is where it got interesting.
Agent mode actually produced better reasoning than base ChatGPT. The analysis was sharper. But I couldn't even run the query without selecting a connector. I picked GitHub, which had nothing to do with the task. The artifacts were slim at best. And it quit on the first visualization attempt.
The model got smarter. The infrastructure around it didn't.
What GPT Actually Produced
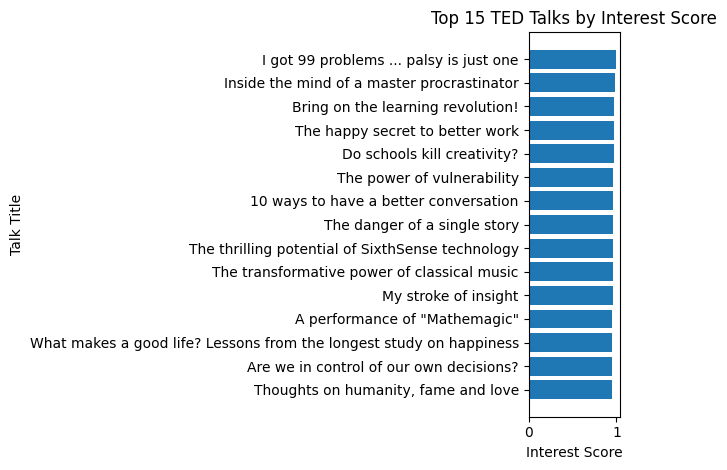
To be fair to GPT, let me show you what it did. The task was: analyze the TED talks dataset and build a defensible ranking approach that's better than just sorting by views.
GPT analyzed the metadata and transcripts and built a composite "interest" score. The top 10:
- I got 99 problems ... palsy is just one — Maysoon Zayid
- Inside the mind of a master procrastinator — Tim Urban
- Bring on the learning revolution! — Ken Robinson
- The happy secret to better work — Shawn Achor
- Do schools kill creativity? — Ken Robinson
- The power of vulnerability — Brene Brown
- 10 ways to have a better conversation — Celeste Headlee
- The danger of a single story — Chimamanda Ngozi Adichie
- The thrilling potential of SixthSense technology — Pranav Mistry
- The transformative power of classical music — Benjamin Zander
The ranking algorithm weighted views (30%), rating quality (25%), comments (15%), languages translated (10%), total ratings (10%), stage response rate (5%), and duration sweet spot (5%), all normalized within publish year to reduce age bias.
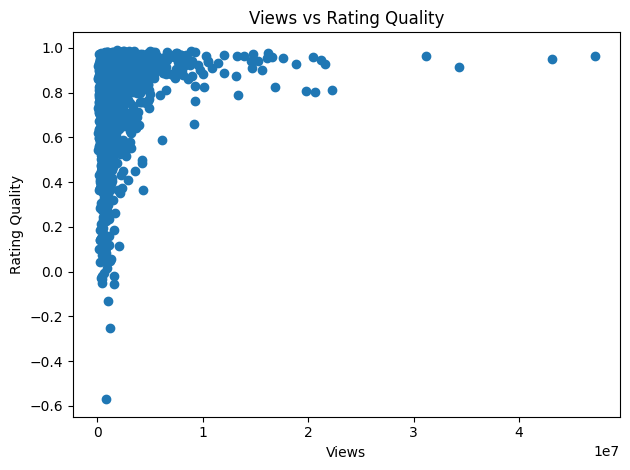
Two things stand out from the scatter: bad talks don't scale (high views almost always means high quality), but good talks don't always scale (low views, high variance in quality). Views are a lagging popularity signal. Ratings are the real quality signal.
This is solid work. The methodology is defensible. The results feel right.
I had to re-run it in agent mode to get these results. The first attempt wasn't good. I needed to push GPT harder for a fair comparison. Even then, it produced solid analysis but stopped at two charts. No category breakdowns. No trend analysis. No interactive exploration. The model reasoned well. The product needed coaxing to deliver.
What Ca$ino Produced
Same dataset. Same prompt. Ca$ino analyzed 2,550 TED talks and built a four-component TED Score (0-100): Popularity (40%), Engagement (25%), Quality (20%), and Virality (15%).
The top 10:
- Do schools kill creativity? — Ken Robinson (66.2)
- Militant atheism — Richard Dawkins (57.2)
- The case for same-sex marriage — Diane J. Savino (52.9)
- Your body language may shape who you are — Amy Cuddy (50.9)
- My stroke of insight — Jill Bolte Taylor (50.8)
- A message to gay teens: It gets better — Joel Burns (50.3)
- Transplant cells, not organs — Susan Lim (47.2)
- Building a park in the sky — Robert Hammond (46.2)
- How great leaders inspire action — Simon Sinek (46.0)
- The power of vulnerability — Brene Brown (45.8)
But the results aren't the point. The output is.
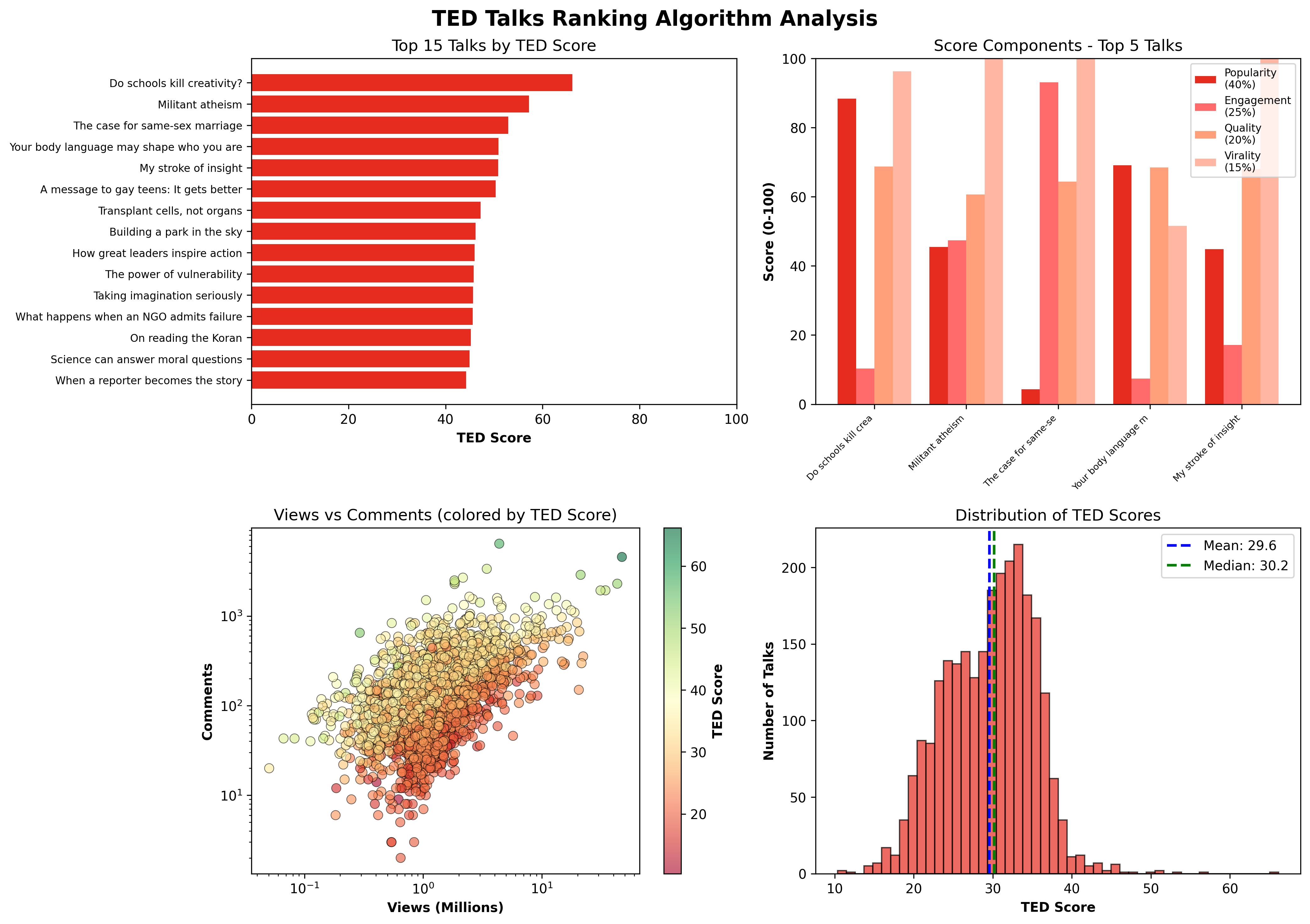
Ca$ino produced four publication-quality visualizations in a single run. A top 15 ranking with scores. A component breakdown showing how each talk earned its position. A views-vs-comments scatter colored by TED Score. And a score distribution histogram showing where the median sits. All saved as artifacts, all downloadable.
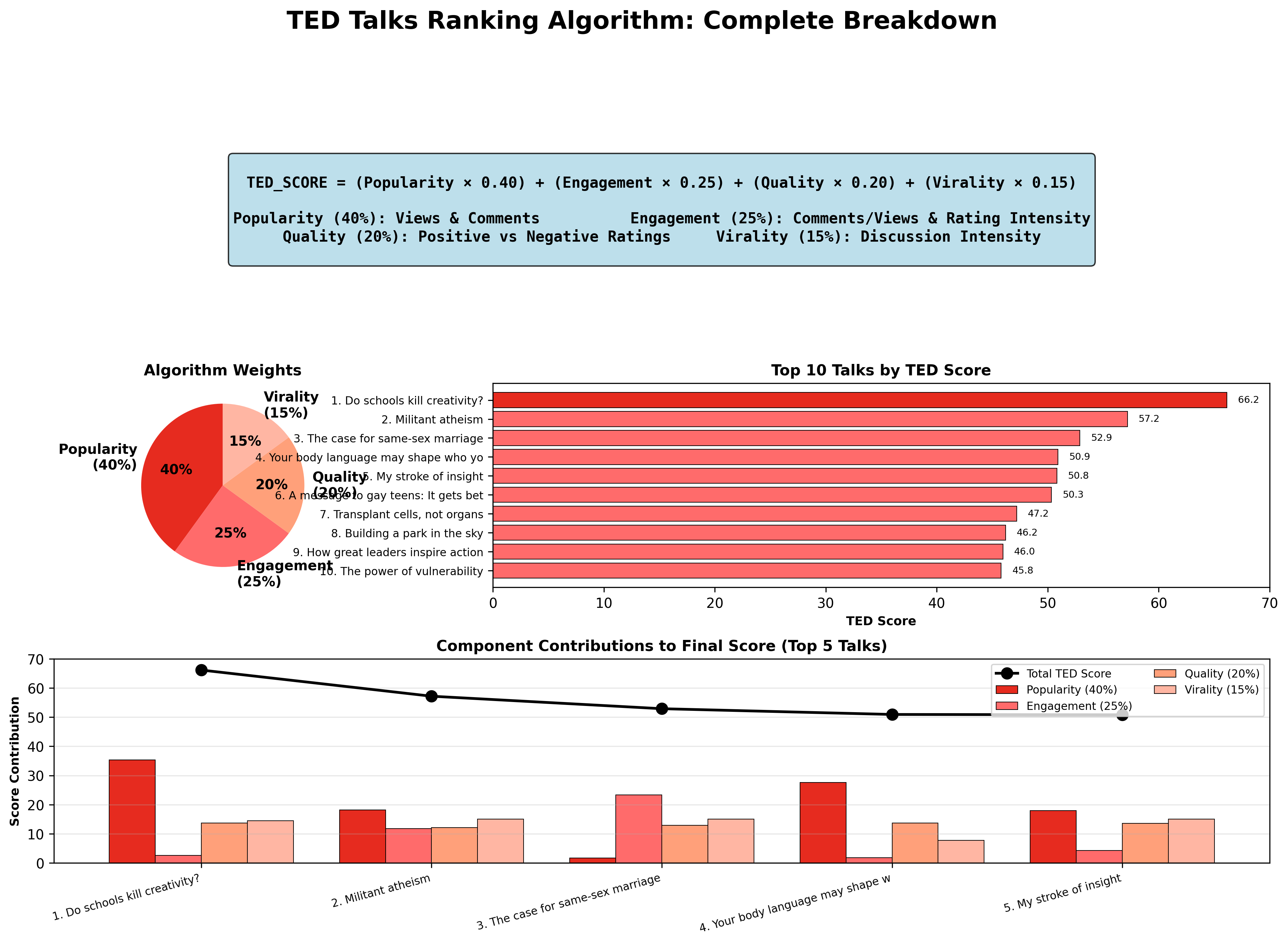
Then it went further. A complete algorithm breakdown: the formula, the weight pie chart, the top 10 with exact scores, and a component contribution chart for the top 5 showing exactly where each talk's score came from. This is the kind of output you'd put in a slide deck.
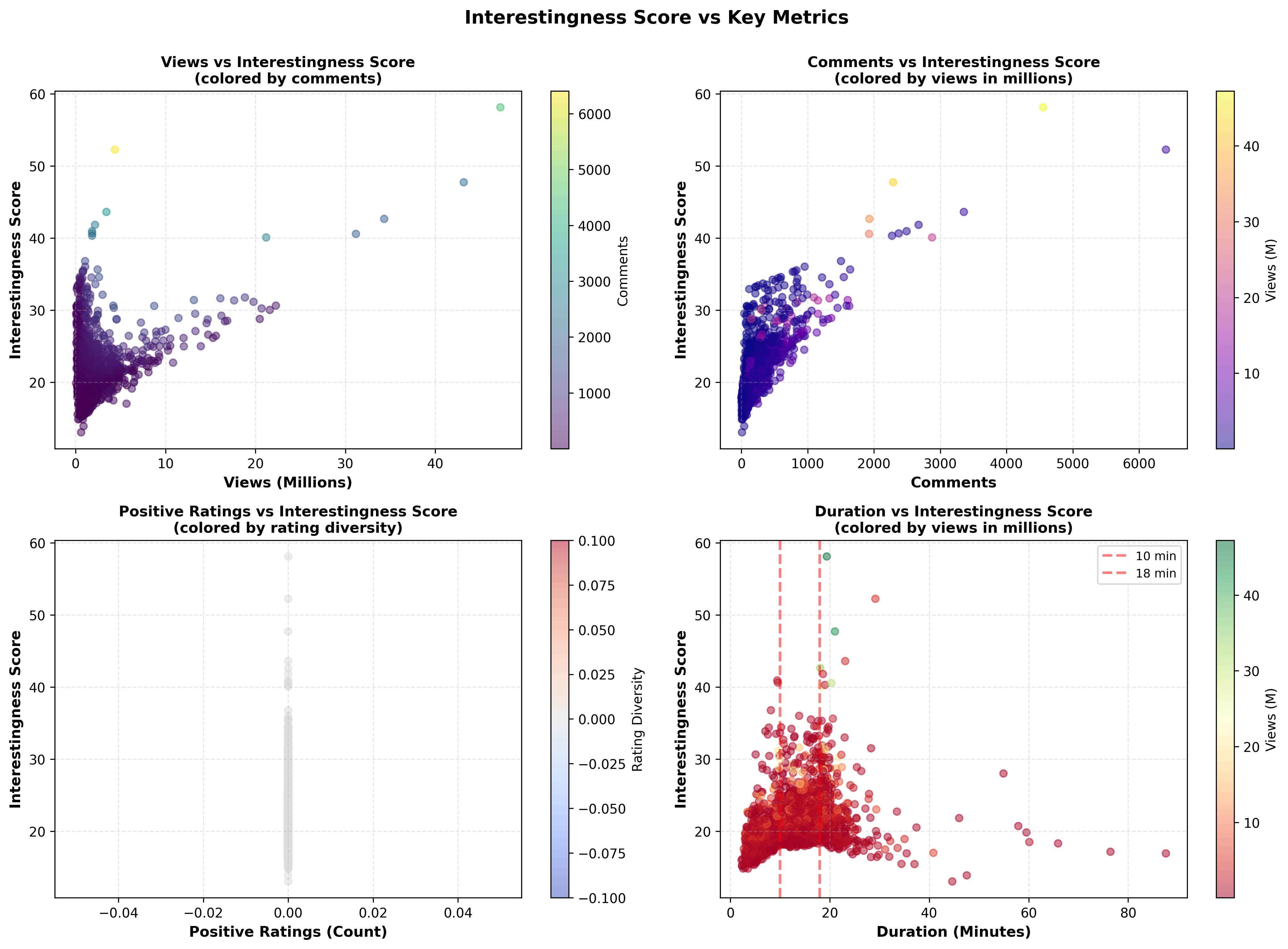
And a four-panel correlation analysis: interestingness vs. views (colored by comments), vs. comments (colored by views), vs. positive ratings (colored by rating diversity), and vs. duration (with the 10-18 minute sweet spot marked). Each panel tells a different story about what drives TED talk quality.
Seven visualizations. One report. One run. Zero failures.
GPT produced a solid methodology with two charts. Ca$ino produced a complete analytical deliverable. Same model underneath. Different infrastructure around it.
Why This Isn't Surprising
When you upload a dataset to ChatGPT, here's what actually happens: one model reads your data, writes Python code, executes it in a sandbox, reads the errors, rewrites the code, and loops until it gets an answer. One brain doing everything, one step at a time, in one context window that fills up with every iteration.
Agent mode is the same model with a longer leash and better reasoning. It can browse. It can use tools. But it's still a single agent switching contexts in a single thread, and it's designed for web browsing and multi-step workflows, not structured data analysis. That's why it forced a connector selection. That's why the visualizations fell apart. The model improved. The product around it is built for a different job.
Ca$ino decomposes the task into specialized agents running concurrently. Each one has a scoped context, purpose-built tools, and a narrow job. The data agent doesn't know about the visualization. The visualization agent doesn't care about the schema. They do their jobs and the orchestrator assembles the output.
Less context pollution. Less attention drift. Faster execution. Better results.
This isn't controversial if you think about it for ten seconds. It's the difference between one person doing five jobs and five people each doing one.
The Fast Fashion Business Model
OpenAI is optimizing for 900 million weekly active users. Every feature they ship has to justify itself across that entire base. A five-agent swarm tuned for analytics teams with a 40-person backlog doesn't clear that bar. It never will.
Zara doesn't make bespoke suits. Not because they can't cut the fabric, because the economics don't work at their scale. OpenAI won't build this for the same reason. They're going horizontal and consumer. Every quarter they move further toward being a platform for everyone rather than deep infrastructure for specific workflows.
That's not a knock. It's a strategic reality that creates a gap. And Altman is telling you this explicitly. He's proud of the fast fashion model. It serves his 900 million users well. But it leaves a specific kind of builder without a factory.
So Who's Building the Factory?
I went looking. The answer is: not quite anyone.
The landscape breaks into three tiers, and the space between them is where the real opportunity lives.
The orchestration frameworks — CrewAI, LangGraph, AutoGen, OpenAI Swarm, Strands. They solve how you build agents. Multi-agent coordination, role-based delegation, graph-based workflows. They're good. But they're frameworks, not platforms. You still have to figure out deployment, security, delivery, and isolation yourself. As of early 2025, only 11% of organizations had agentic AI in full production, even though 99% said they planned to. That number has climbed since, but the gap between "built an agent" and "deployed it" persists. This is why.
The enterprise mega-platforms — OpenAI just launched Frontier. Salesforce has Agentforce. Microsoft has Agent 365. Google has Vertex AI Agent Builder. NVIDIA announced NemoClaw at GTC. These are the horizontal plays. Frontier wants to be the "operating system of the enterprise," connecting CRMs, data warehouses, ticketing tools, and treating agents like digital employees with onboarding and permissions. It's impressive. It's also designed for Fortune 500 companies with dedicated OpenAI account teams and Forward Deployed Engineers. If you're not Uber or State Farm or Intuit, this isn't built for you yet.
The middle layer — purpose-built agent infrastructure for specific workflows with scoped deployment, ephemeral delivery, and container isolation. This is the tier that doesn't exist. The frameworks assume you'll figure out production yourself. The platforms assume you're a massive enterprise. Nobody is building for the team that needs five specialized agents running a specific analytical workflow, deployed in isolated containers, delivering output through presigned URLs that expire in an hour.
The frameworks give you the agents. The platforms give you the governance. Nobody gives you the infrastructure between them. Nobody's building the factory.
The Delivery Problem Nobody Talks About
This is the part that gets overlooked because it's not as sexy as the orchestration layer.
GPT's delivery model is built for consumers. Code Interpreter runs server-side in a sandbox, but Canvas renders client-side via Pyodide in the browser. Shared conversation links persist indefinitely (until you delete them). Code Interpreter file downloads expire within the hour when the sandbox session ends. There are no scoped permissions. A shared link is full access. No audit trail beyond what OpenAI logs internally.
A presigned S3 URL through CloudFront gives you time-bounded access (1-hour default, configurable), tenant-scoped permissions, no code execution on the client, and a full audit trail via CloudFront access logs. The link dies. You own the logs. The requester never touches your backend.
If you're delivering analytical output to a client or a stakeholder, the delivery mechanism is infrastructure. And right now it's an afterthought, if it's thought about at all.
Ca$ino Is a Proof of Concept. The Thesis Is the Point.
Ca$ino is not a company. It's an open-source composable agent I built on Strands to test a hypothesis: that a purpose-built swarm with scoped infrastructure would outperform a general-purpose model on a specific workflow. It did. Convincingly.
But I'm less interested in the agent than in what the experiment reveals about the landscape. The middle layer is empty. The infrastructure between "I built an agent" and "this is production-ready for my team" doesn't exist yet. Not really.
Someone is going to figure this out. The frameworks are maturing fast. The enterprise platforms are pushing downmarket. CrewAI already has a control plane. Frontier is expanding access. The pieces are all on the board. The moment someone stitches together deployment, isolation, scoped delivery, and workflow-specific orchestration into a single layer, and makes it accessible to teams that aren't Fortune 500, the game changes.
Sam Altman says we're entering the fast fashion era of SaaS. He's right. But fast fashion only works if the factory is solid. And nobody's building the factory.
Update: The Thesis Proved Itself
I published this post on March 25. The same day, OpenAI announced it's shutting down Sora.
You can't make this up. Six months after launch, the viral AI video app is being killed as OpenAI reels in costs ahead of its IPO. The numbers tell the story: downloads plunged 45% by January. Lifetime revenue from in-app purchases was roughly $2.1 million, for a product reportedly costing $15 million per day to run.
The Disney situation is almost comical. Disney had announced a $1 billion investment in OpenAI tied to Sora. On Monday evening, Disney and OpenAI teams were working together on a Sora project. Thirty minutes after the meeting, the Disney team learned OpenAI was pulling the plug. No money ever changed hands. "The deal is not moving forward."
This is the entire thesis in a headline. Sam Altman says "fast fashion SaaS." Then his own product becomes the fast fashion. Shipped it, went viral, downloads cratered, killed it six months later, rug-pulled Disney on a billion-dollar deal with 30 minutes notice.
That's what happens when the economics of mass production meet reality. The product was impressive. The model was impressive. But it was a consumer play consuming enterprise-level compute with no infrastructure underneath it. No sustainable business model. No vertical depth. Just vibes and downloads.
And now everyone who built workflows around Sora, every creator, every brand, every team that integrated the API, is scrambling to preserve their work before the lights go off. That's the cost of building on fast fashion.
I'm advocating for the opposite. Infrastructure that persists. Delivery that's scoped. Outputs that don't disappear because someone's IPO math changed.
I wrote about the full thesis here. This experiment is the first proof point. Sora is the second.